In this work, we ask the following question: can self-training — the process where a language model learns from its own judgments — can be sustained within a RL framework?
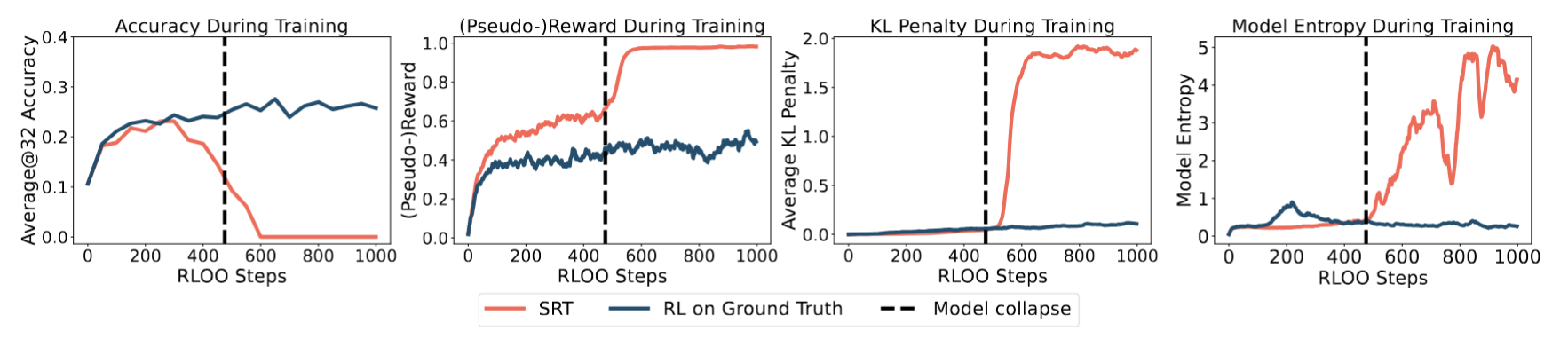
On a comprehensive set of experiments on both synthetic and real reasoning tasks, we find that this basic approach has the capability to improve not only the model's reasoning performance, but also its potential of generating better quality feedback for the next RL iteration, driving further model improvement. Yet our analysis also reveals a critical limitation of such a self-training paradigm — prolonged RL with self-reward leads to reward hacking where models learn to maximize training (pseudo-)reward, resulting in sudden performance collapse.
Together, these results highlight feedback design as the central challenge and call for future research on mechanisms to enable prolonged self-improvement.
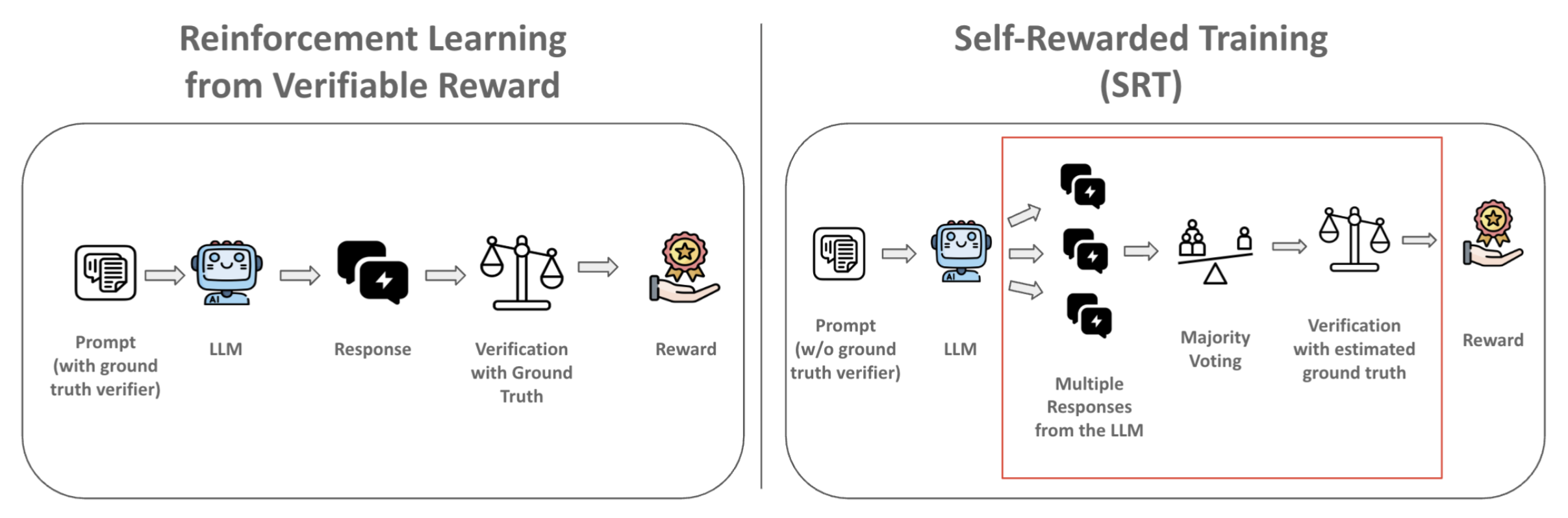
(1) Self-Rewarded Training (SRT)
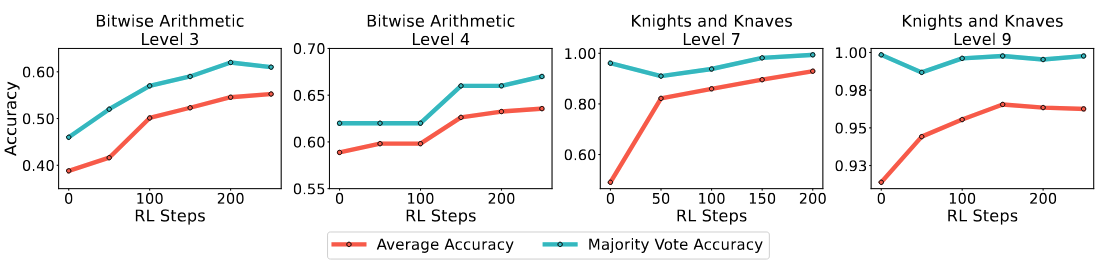
(2) Self Training Can Improve Both Performance and Feedback Quality
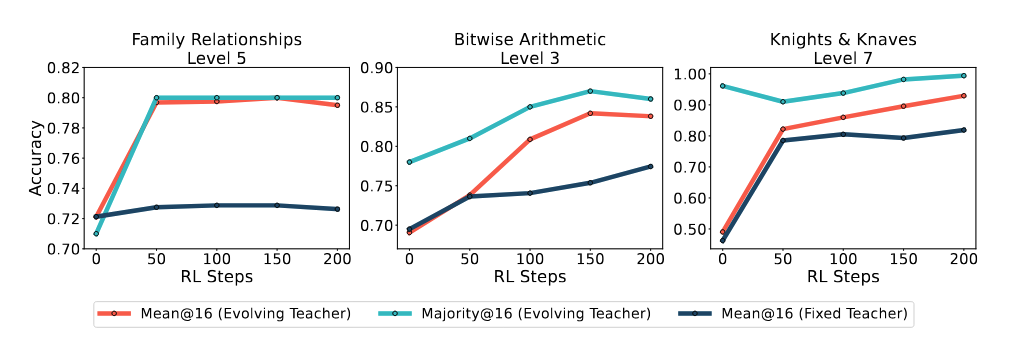
To ensure the model understood the task and output format, we first trained it with RL using ground-truth data from the previous difficulty level before proceeding to label-free SRT training.
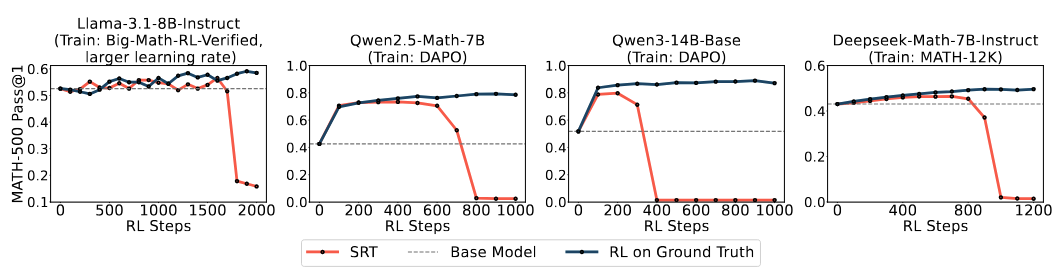
(3) SRT Works on Real-World Reasoning Tasks
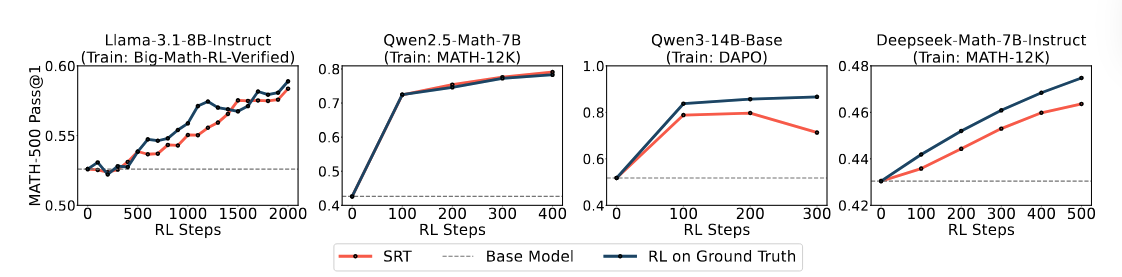
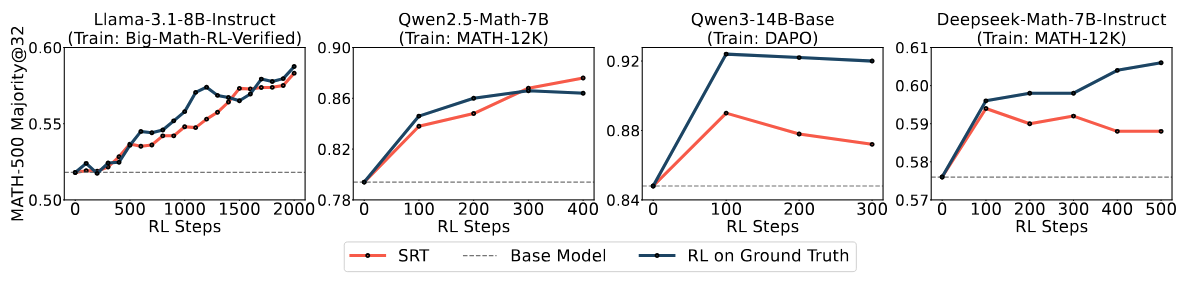
(4) Can Self Improvement Be Sustained Indefinitely?

Conclusion
Takeaway 1
On both synthetic and real reasoning tasks, SRT improves average and majority voting accuracies, showing ability gains beyond the base model. Specially, improvement in majority voting accuracy also signifies improvement of the quality of self-supervision during training demonstrating a promising path forward to self-improvement.
Takeaway 2
The question of whether self-training can be extended indefinitely has mixed results: while under controllable difficulty (Reasoning Gym), SRT has the potential to keep improving beyond the base model on progressively more difficult tasks, while training on real-world math problems demonstrate the phenomenon of reward hacking — sustained self-improvement requires developing additional regularization measures to be effective.
Related Literature:
Several works explore self-training LLMs, some of which are concurrent. A non-exaustive list includes:
- Zeikerman et al. (2022) and Huang et al (2022): demonstrates that LLMs can self-improve by training on chain-of-thoughts from a previous instance of the model. Particularly, Huang et al., 2023; Wang et al., 2023a; Prasad et al., 2024 demonstrated the feasibility of using majority voting and self-consistency to filter chain-of-thought traces that, when used as SFT training data, improve the LLM performance on downstreaming tasks.
- TTRL (Zuo et al., 2025), proposes a test-time training algorithm, which is equivalent to SRT used at test time.
- Similarly, Zhao et al., 2025 incorporates token certainty as a training signal.
- Shao et al., 2025 shows that RL with spurious reward can lead to a performance boost for some LLMs.
BibTeX
@misc{shafayat2025largereasoningmodelsselftrain,
title={Can Large Reasoning Models Self-Train?},
author={Sheikh Shafayat and Fahim Tajwar and Ruslan Salakhutdinov and Jeff Schneider and Andrea Zanette},
year={2025},
eprint={2505.21444},
archivePrefix={arXiv},
primaryClass={cs.LG},
url={https://arxiv.org/abs/2505.21444},
}